
- Repository for this project: Github
- python file for training ConvNet:
FCN512_2.py - Jupyter notebooks used for image learning and plots:
Learn_image.ipynb,Generate_plots.ipynb
In Brief
- In deep generative modeling, Texture synthesis is the process of creating novel texture images. Texture extraction involves taking a natural image and producing images with qualitatively similar texture properties.
- In this project, I develop a novel texture extraction model that uses image-learning-based techniques. This makes it similar to something like the original neural style transfer process. However, I employ a texture descriptor based on global average pooling across convolutional channels. This descriptor effectively captures how all convolutional filters in a (pre-trained) fully convolutional network (FCN) are activated. I first train a generative FCN (structured like an autoencoder) on a lichen photo dataset that I created. I then iteratively optimize a texture image until its texture descriptor vector matches that of a target image.
- Research question: 1. How does my novel texture descriptor perform?–what will the synthetic images derived from it look like? 2. What effect does the FCN’s training data have on the textures generated?
- Result: When learning a new texture image, my model captures the color distribution of the target image well. The spatial features in the learned image do not reflect those in the target image very well. However, the nature of the training data had an obvious impact on the appearance of textures that could be generated.
- In part 1/2 (this post): I’ll give a broad overview of the different paradigms in deep generative modeling, as well as some alternative texture extraction models from the literature that had better performance. This is useful since it classifies my own model and contrasts it with fundamentally different methods such as GANs.
- In part 2/2: I’ll cover my dataset, network architecture, image learning algorithm, and results.
What are textures?
I’ve been interested in what I call “textures” for many years. I formally describe textures as nonrepeating variation of some value such as color over space. For example, sand on a beach, bark on a tree, grass, or the surface of a lake with many ripples. The unifying properties that make all these phenomena textures is that they are qualitatively self-similar everywhere but non-repeating. What I call “patterns” (such as a checkerboard, a knitted fabric, or a tessellating tiles) are different in that they have mathematically well-defined repeating structure. To use mathematical language they are periodic in some way.
Way before learning deep learning, I had wondered about how textures could be mathematically described. I did not have much success, however, until the ideas of generative modeling came along. Generative models can not only model textures from existing images (texture extraction), they can interpolate between textures and even synthesize completely novel textures.
Research Objective and Brief Methods
Is it possible to take a natural image and “extract” the textures within it? I.e Can we generate images containing new instances of those textures? This texture synthesis, or more specifically, texture extraction is one of many challenging computer vision tasks that has been advanced substantially in recent years by convolutional neural networks (CNNs). The authors of Learning Texture Manifolds with the Periodic Spatial GAN describe it this way
The goal of texture synthesis is to learn from a given example image a generating process, which allows to create many images with similar properties.
In this project I develop and evaluate a novel texture extraction method that is image-learning-based, meaning we optimize (learn) the pixel values of an image directly by iteratively applying gradients to the image. This procedure is in the same spirit as convolutional filter visualization and neural style transfer, covered in the sections below.
I ask whether a novel texture descriptor based on global average pooling across all convolutional channels can capture qualitative features of the texture in a target image. I also ask how the original data that the convolutional network was trained on affect the textures that can be generated.
The learned texture image is optimized such that, when fed into a pre-trained fully convolutional network (FCN), it activates filters in a similar way as the target image. That is, after image learning, feeding the target image and the learned image to the FCN should produce similar texture descriptor vectors. The FCN is an autoencoder that was trained to reconstruct its inputs. It was trained on a dataset of lichen macro photography that I created. In order to focus on textures, each training image is a 512 x 512 pixel patch from one of the full-sized photos.
Related Generative Models, organized by paradigm
In order to place my texture extraction method in the wider context of deep generative modelling, I’m going to describe a few of the major paradigms that I’ve come across, along with examples of each. These categories refer to the way that the actual image synthesis step takes place, disregarding all steps leading up to it (such as training a model). I can summarize them as follows.
- Image learning: optimizing (i.e. learning) the pixel values of an image directly by iteratively applying gradients to the image. Typically the gradient of some loss function is taken with respect to the input image itself. The resulting gradient tensor has the same shape as the image being learned and it is added to the image until the loss is minimized.
- Single-forward-pass: The image is generated by a single forward pass of some data through a generator network that tends to involve upsampling. The input to the generator network is often a latent vector or tensor, which encodes higher-level features of the image being generated in a compressed format.
- Intermediate product: The image being generated is the output of an intermediate layer in a model. The image may be a byproduct of optimizing some loss function that does not involve the image itself. There is one key example I’ll reference later which does not fit into the first two paradigms.
Image learning
Filter visualization
One instance of image learning is convolutional filter visualization. In this algorithm we begin with a trained CNN (for example, a network like VGG trained for image classification). We then define a loss function based entirely on how strongly some particular filter responds. This can be accomplished by setting the loss equal to the sum over all pixels in the filter’s corresponding feature map or channel. The gradient of this loss with respect to an input image is then applied to the image itself. Over many iterations, the image (initialized as noise), changes such that it more strongly activates the filter being visualized. The process is called activation maximization. There is a wonderful guide to this process using keras in this François Chollet notebook and this Distill article
 Fig. See Distill article
Fig. See Distill article
Style transfer
Another notable example that uses image learning is the original style transfer algorithm. My method (see part 2/2) takes a very similar approach to this. Without going too in depth, style transfer uses a loss function composed of two main components: a content loss and a style loss. The content loss measures the structural similarity between the image being learned and a target ‘content’ image. The style loss measures the similarity between style descriptors derived from the learned image and a third, ‘style image.’ (The style of the style image will be transferred to the learned image). The style descriptor is based on gram matrices that contain information on the relationships among convolutional channels. Ultimately, the three images (learned image, content image, and style image) are sent through a pre-trained model and the gradient of the loss is taken with respect to the learned image. Finally, the gradient is applied to the learned image, the updated image is sent back into the model to compute the new loss, and the cycle repeats. This was obviously an extremely condensed summary.. Please see the papers and this Notebook for a guide to implementation in keras.

DeepDream
The famous deep dream images are also produced by image-learning methods. The input image is incrementally adjusted so that it more strongly activates high-level neurons usually involved in classification.

Fig. https://en.wikipedia.org/wiki/DeepDream
Single-forward-pass
This group of methods ultimately generate an image using a single forward pass through a trained generator network. Examples include the decoder network in variational autoencoders (VAEs) and the generator network in generative adversarial networks (GANs). Another example is what you could call “fast style transfer,” where style transfer is framed as an image transformation problem instead of an image optimization process. In these cases, the network parameters needed to generate an image were typically learned prior to the image synthesis step.
“Fast style transfer”
The authors of Texture Networks: Feed-forward Synthesis of Textures and Stylized Images were able to increase the speed of style transfer by orders of magnitude by training a generator network that could apply a style to an input image with a single forward pass. From their abstract:
Gatys et al. recently demonstrated that deep networks can generate beautiful textures and stylized images from a single texture example. However, their methods requires a slow and memory-consuming optimization process. We propose here an alternative approach that moves the computational burden to a learning stage.
Perceptual Losses for Real-Time Style Transfer and Super-Resolution contains similar work.
VAE decoder network
In autoencoders and VAEs, an encoder and decoder network are connected at an information bottleneck in the middle (See my posts for more details and resources on VAEs). The decoder network is trained to reconstruct the encoder’s input image from the relatively small latent vector produced by the encoder. After training, the decoder can act as a generator of novel images. Ideally, one can sample new latent vectors and feed them to the decoder to generate new images. The hope is that these images will look as if they are drawn from the same high-dimensional distribution as the training images.
GAN generator network
The process of training GANs is beyond the scope of this article, but I’ll just note that image synthesis using GANs also results from a single forward pass through the generator component of a GAN. During training, latent tensors, whose components are drawn from uniform or gaussian distributions, are provided to the generator network. The generated image (or a training image) is fed to the discriminator network, and the GAN loss function is computed based on the discriminator’s predicted probability that the image was a real training image. I believe GAN-based methods are state of the art in texture extraction and there is a beautiful example in this paper which is far superior to mine: Learning Texture Manifolds with the Periodic Spatial GAN. In future work I would use their method as a starting point.
Intermediate product
Finally, I know of at least one example that involves neither direct image learning nor a single forward pass. In Synthesizing the preferred inputs for neurons in neural networks via deep generator networks, the authors
…synthesized [images] from scratch to highly activate output neurons in the CaffeNet deep neural network, which has learned to classify different types of ImageNet images.
What made this work novel was that the generated images looked more like realistic natural images than what had been done previously (Figure 1).

The previous methods had used neuron activation maximization and image learning alone. However, in this work the generator from a pre-trained GAN effectively conditioned the generated image to look like a natural image. This conditioning was applied by optimizing an input latent vector(shown in red in Figure 2) so that a particular class (in this case “candel”) was strongly activated. To me, this is a very interesting approach since you are essentially obtaining the image as a byproduct of optimizing something else. It also illustrates the core concept of “conditioning” in generative modelling.
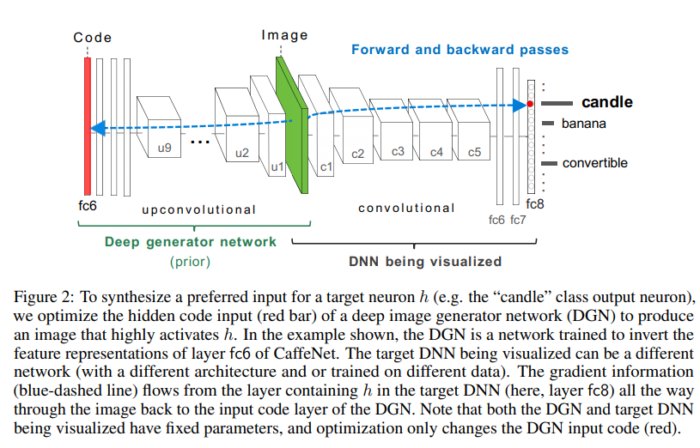 Figures borrowed from Synthesizing the preferred inputs for neurons in neural networks via deep generator networks
Figures borrowed from Synthesizing the preferred inputs for neurons in neural networks via deep generator networks